如何设计一个精简版的微博(或者Twitter)?
问题描述
设计一个精简版微博,具有发布微博、关注用户和收藏微博的功能。
进一步沟通和细化需求
对于以上的描述,距离可以动手的程度还有些距离,以上的描述还是有很多维度的信息需要具像化。
我们需要从下面这些维度进行沟通和细化:
- 用例
- 用户量
- 主要操作及频度
- RPS、QPS及TPS
- 读写比
- 数据规模(如果有的化)
用例
首先,从之前的描述来看用例是相对比较清楚的:
核心功能用例
- 发布微博
- 关注用户
- 收藏微博
- 显示用户数据和微博数据
非功能用例
- 系统高可用(HA)
次级功能用例
- 删除微博
- 取消关注用户
- 取消收藏
系统约束条件
这一部分需要进行沟通,
如果是面试环境下,这个沟通的对象会是桌子对面的面试官;
如果是实际的产品功能沟通会场景,这个沟通对象可能会是产品经理、业务负责人甚至是CEO;
当然不同的背景的沟通对象对于同一问题的沟通话术和技巧会不同,但是不管是对方是怎样的沟通对象,沟通的原则是“换位思考,站在对方的角度去沟通对方关注的价值”。
看起来这个是一个简单的环节,但是在实际的工作中这一步其实是比较复杂的环节,这里就不展开进行论述。以下我们假设沟通环境是开放和透明的,所提供的信息是准确的。
- 用户量
我: “这样的微博系统,用户量级会是怎样的?”
面试官: “嗯,这是个好问题,我们可以考虑这个系统是这样的量级,DAU: 1000w, 每天有1亿HTTP请求”(注:根据2018年新浪微博披露的数据 DAU 大概在5000w)
$$ RPS = 10000w / (24 * 60 * 60) \approx 1000 $$
- 用户关注关系规模(社交网络好友关系数据规模)
我:“用户的关联度是怎样的?每个用户平均会有几个关注者?”
面试官: “每个用户平均会有200个关注者,当然会有影响力比较大的KOL会有1000+的关注者”
用户好友关注关系数据规模 = DAU * 200 = 20亿
- 主要操作 - 微博发送数量、收藏数量
我: “微博发送、收藏量的数据规模是怎样的?”
面试官: “嗯, 每个用户平均每天发1条微博,收藏2条微博”
根据之前沟通的DAU数据,可以估算得出:
发送微博数量 = DAU * 1 = 1000w / 天
收藏微博数量 = DAU * 2 = 2000w / 天
粗略估计读写比 10000W - (1000W + 2000W) : (1000w + 2000w) = 7:3
阶段1产出物
- 用例:
| 类别 | 用例 |
|---|---|
| 核心功能需求 | |
| 发布微博 | |
| 关注用户 | |
| 收藏微博 | |
| 展示用户和微博数据 | |
| 非功能性需求 | |
| 高可用 |
- 设计约束:
| 约束 | 数据 |
|---|---|
| 日活跃用户数 | 1000W |
| 日用户关注数据规模 | 20亿单位 |
| 每日发送微博数 | 1000w |
| 每日收藏微博数 | 2000w |
| 每日HTTP请求数 | 1亿 |
| RPS | 1000 |
| 读写比 | 7:3 |
| 激增流量 | 对于某些用户和微博会有瞬时的激增流量风险 |
概要设计(High Level Design)
在开始概要设计之前我们将上个阶段分析得出的用例在这里展示出来:
| 类别 | 用例 |
|---|---|
| 核心功能需求 | |
| 发布微博 | |
| 关注用户 | |
| 收藏微博 | |
| 展示用户和微博数据 | |
| 非功能性需求 | |
| 高可用 |
从现有的简单需求来看,系统做两层分层就足够,
- 逻辑层
- 数据持久层
其中逻辑层主要负责请求的处理和必要数据的整合组装, 数据持久层负责将逻辑层处理后需要持久化存储的数据进行存储和获取。
逻辑层概要设计分析
在概要设计阶段我们先不考虑逻辑层内的具体实现,需要重新结合之前得出的设计约束来看下这一层在功能和非功能性需求上有哪些需要解决的问题?这一层上主要是处理用户请求,结合之前分析得到的 日请求数、RPS的数据,我们知道这个系统平均每秒会有1000个请求,而对于这样的系统,请求的分布也一定不是平均分布的,所以合理的假设是日常的请求水平是这个平均数的10倍,也就是 QPS = 1w Reqs / second
这样的一个量级其实也是在单机性能可承受的范围内(考虑 经典的C10k问题、及近些年来的C10m问题),考虑到之后的系统的可伸缩性(Scalability),所以在这一层的系统概要设计就需要考虑系统的可伸缩性。
在系统伸缩性的考虑上有两个可考虑的手段
- Scale up(纵向伸缩)
Pros:
操作直接,无需对现有系统做修改(或者是仅需少量修改)
Cons:
纵向伸缩的操作会受限于硬件设计的技术极限和财务角度的限制,
- Scale out(横向伸缩)
Pros:
适合系统负载明显递增的情况
增加系统应用实例抗击风险能力,提高应用实例的系统可用性
Cons:
一定程度上增加系统的复杂性
综合之前对系统需求沟通中有激增流量的场景,这里的逻辑层适合采用 Scale out 的方式进行系统伸缩, 常见的解决办法就是在逻辑层添加负载均衡(load balancer)
数据持久层设计分析
下面来考虑数据持久层,首先是这一层可选的持久存储的方式:
文件? 在需求分析阶段其实会发现有明显的实体-关系结构,所以使用关系型数据库会比较自然,但是使用非关系型数据库好像也未尝不可(业务中没有对事务的依赖和强需求),以下的设计就暂时使用关系型数据库的选型进行。
这里对需要持久化存储的数据规模做一个估算:
首先是新增微博:
每日新发送微博会有 1000W 条,为了简化问题我们假设微博对单条微博的字数限制为140个字,每个字按4Byte大小计算,字符的存储不考虑字符的压缩,那么每天的新增微博数据存储数量会是:
$$1000w * 140 * 4 Byte \approx 5.6GB$$
其次是用户关注:
用户关注的数据的数量级在 1000W * 200 = 20亿
用户关注部分的关系数据主要是两个Int类型的用户Id,在加上表的主键,一条记录按12Byte计算
所以这部分的数据规模是 20亿 * 12Byte = 240W KB = 2400MB = 2.4 GB
再次就是微博的收藏:
与用户关注计算类似,我们有:
2000W * 12Byte = 24W KB = 0.24 GB
可以看的出来存储的数据中微博内容的存储会是主要的部分。
而且对于微博内容数据存储我们做一个年存储量的估算:
$$5.6GB * 365 \approx 2TB$$
这样的一个单表量级尚未达到MySQL和Linux操作系统单文件大小限制(16TB - EXT4 on RHEL What are the file and file system size limitations for Red Hat Enterprise Linux?)
所以,在这个维度上MySQL(Oracle)这样的关系型数据库是能够胜任的,只不过数据发展到必要的时期需要做一些数据库上的技术改造(Sharding or Partitioning)
V0.1 系统设计架构图
所以我们现在根据之前的分析和系统概要设计分析,得出这样的一个系统架构图:
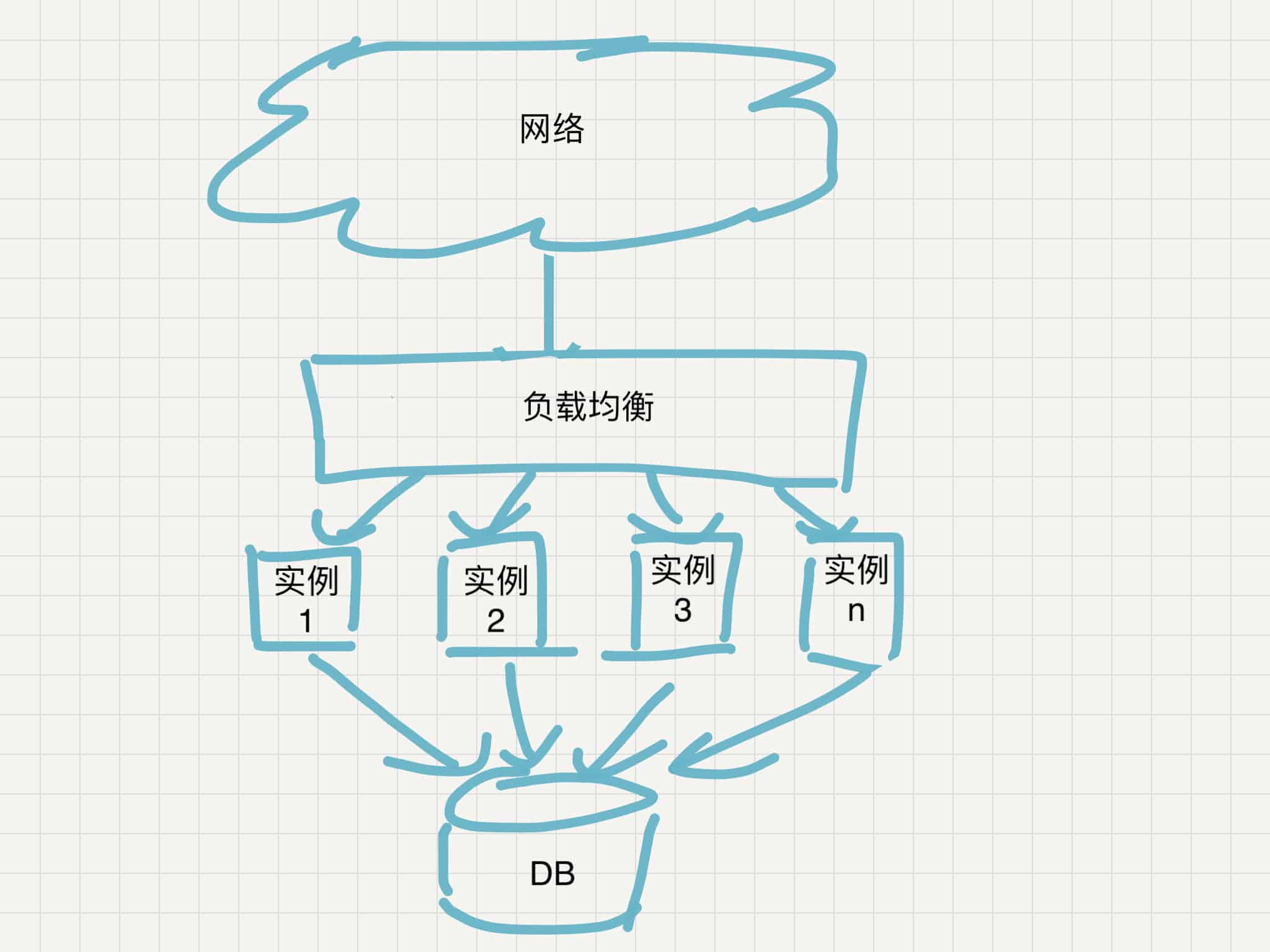
正所谓一图胜万言,相信有了这样一个基础就可以抛砖引玉,引出后面系统的演进。
其实仔细回顾用例和设计约束,还有部分仍然未满足。至少非功能性需求“高可用”在目前的设计中并未完全满足。
另外,从功能的角度以上的设计也存在问题,作为一个具有社交属性的 news feed 系统,用户登录是隐含功能,有了用户登录,就需要cookie-session的机制,一般来说session是以临时文件的形式存储在应用实例上的,如果在应用实例上做 Scale out,那么遇到的第一个问题就是:
- session 共享(shared session)问题
如何解决这个问题呢?
常见的思路就是提取一个供应用实例共享的 session 存储读取服务。
对于这样的存储服务,我们可以选型:
- 文件
- NO-SQL
- SQL
如果是文件,需要考虑的是高可用的方案,简单的文件高可用可以选择RAID(RAID0, RAID1, RAID5 RAID6, RAID10), 如何选型RAID可以参考 Redundant Array of Independent Drives
如果是NO-SQL、SQL可以考虑CPA中的AP存储方案。
这部分的详细设计方案在后续的步骤演进中细化。
在解决了 shared seesion 问题后,我们回去审视用例和设计约束,我们发现其实还有一个问题我们还未处理,在读写比较高的业务场景下,为了减少下层存储层负载使用缓存会是一个比较合适的选型选择。
所以我们可以在逻辑层与持久存储层之间引入缓存层,于是系统架构设计图就有了第二个版本:
阶段2产出物
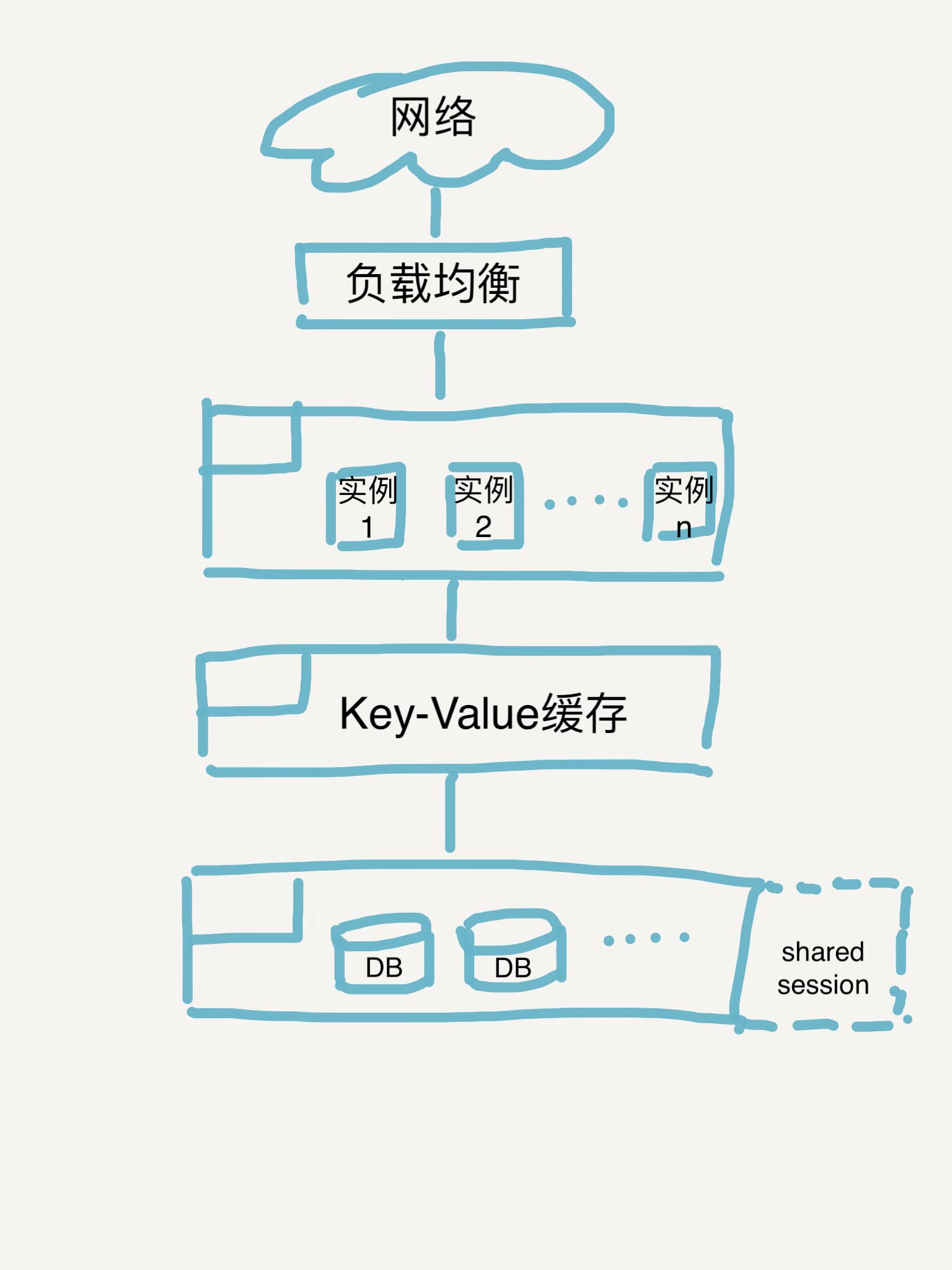
识别单点故障,进行系统扩展
审视着阶段2的系统架构设计图,对照着高可用的目标,我们看现在的设计中还有什么单点故障风险?
好像负载均衡本身会是整个系统中的孤立单点,如果需要解决这个单点问题,我们可以在DNS阶段做负载,DNS根据合理的策略选择将流量导向部署了以上系统架构的数据中心。
好的,到了这一步我们的系统已经从最开始的简单单体架构演进成为了多数据中心多活的系统架构,
阶段3产出物
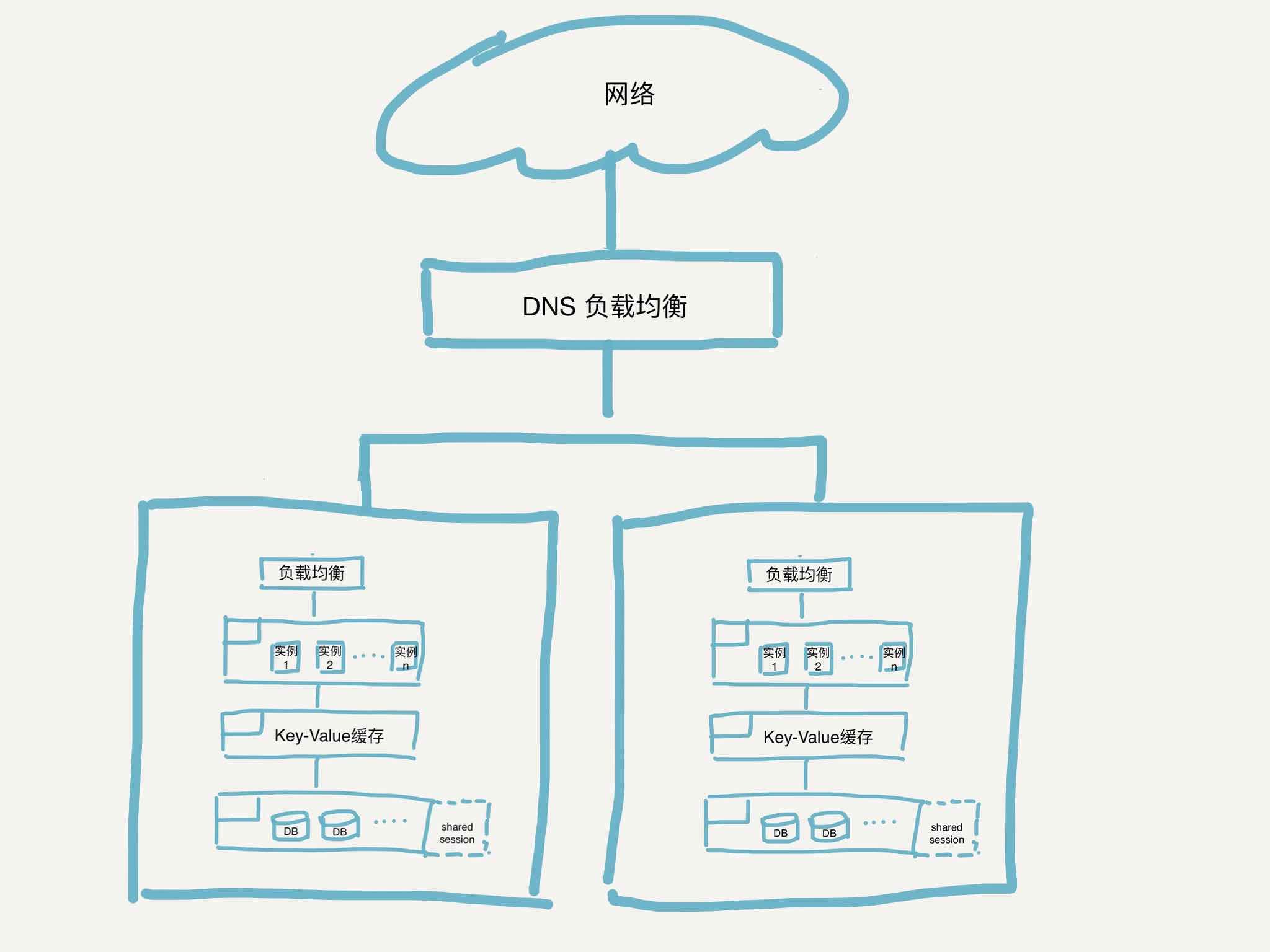
关键组件详细设计
逻辑层对外接口
RESTful API
- 获取用户信息
GET /api/user/
- 获得关注人列表
GET /api/user/
- 关注某个用户
POST /api/user/
1 | { |
- 获得粉丝列表
GET /api/user/
- 获取用户订阅的微博
GET /api/user/
- 发送微博
POST /api/user/
1 | { |
- 收藏微博列表
GET /api/user/
- 收藏微博
POST /api/user/
1 | { |
持久层Schema设计
实体表
- t_user
1 | id: 123, |
- t_posts
1 | id: 123, |
关系表
- t_user_relations
1 | id: 123, |
- t_posts_favorits
1 | id: 123, |
阶段4产出物
RESTful API文档
数据库实体-关系设计图
进一步思考
应用实例 - 关于消息传播的触发方式
以上我们在进行设计都是基于 pull on demand 的“拉”模型,下面我们按照pull模型,分析下这个“拉”的过程:
如果每个用户发出的微博是一个时间线,那么这个用户所能看到的时间线内容就是这个用户关注人时间线按照一定业务规则(比如时间)合并后的时间线。
扩展下,如果时间线是数组(或者是链表),那么这个合并时间线的问题实际上就是一个典型数据结构算法问题。
总结一下,如果是拉模型的话需要解决的就是
- 如何合并多个时间线(Merge k Sorted Lists)
这里就不展开解这个算法问题了,说一下算法思路:
k 个lists的问题最终还是回到两个Lists的合并问题,对于两个Lists的合并问题其实就是一个比较基础的问题了。
具体的实现可以参考:Github - algorithmPlayground - mergeKLists
以及对应测试用例:Github - algorithmPlayground - testMergeKLists
当然消息传播的触发模式除了“pull on demand” 之外 还有 “push on change”,至于两种方式有何利弊,该如何选择?可以参考这篇文章Why Are Facebook, Digg, And Twitter So Hard To Scale?
shared session 问题的考虑
其实在这里,我们可以有一个方案将session持久化到 缓存层(caching tier),使用Redis做 in-memory cache,同时对于session持久化的需求可以单独开辟一组Redis实例使用RDB或者AOF方案,详细的两种方案的对比可以参考Redis Persistence
数据库的伸缩
数据库的伸缩问题实际上是一个比较通用的专题,后续会有文章单独介绍。
缓存的设计
同上,会有后续文章介绍。
突发的流量激增该怎么办
从现在的系统架构来看,基本上消除了单纯的单点故障风险,而常见的业务中会有某些名人或者热点事件带来的突发流量激增,怎样应对这样的风险? 怎样在出现流量激增的趋势之前自动伸缩?
这个问题的解决思路是:
首先需要建立完备(或者是必要)的组件、服务监控。
其次如果需要在一定的SLA的可用度(比如 99.99%)这就需要运维不能依赖人工操作,适时考虑类似K8s等数据中心OS进行自动化扩容。
未完待续
