prompt engineering 101
- 1. 基础
- 2. 提示词相关概念
- 2.1. 零样本(zero shot)
- 2.2. 少样本(few shot)
- 2.3. 思维链(Chain of Thought(CoT))
- 2.4. 计划-解决提示(Plan-and-Solve Prompting)
- 2.5. 自我一致(self consistency)
- 2.6. 思维树(Tree of Thought)
- 2.7. 检索增强生成 (Retrieval Augmented Generation (RAG))
- 2.8. ReAct
- 2.9. 自动推理并使用工具(Automatic multi-step Reasoning and Tool-use (ART) )
- 2.10. 方向性激励提示(Directional Stimulus Prompting(DSP))
- 3. 参考
基础
通用技巧
提示词元素
指令(Instructions)
需要模型做的任务或指令(分类,总结,提取,翻译 等指令/任务关键词)上下文(Context)
能够引导语言模型更好响应的信息或额外信息输入数据(Input Data)
输入的内容或问题输出指示(Output Indicator)
指定输出的类型或格式
放之四海的通用技巧
清晰的指令
- 在提问之前先给LLM一个人设
- 在提问时尽可能给定问题的详细信息和限定条件
- 在提示词中清晰描述用什么分割符区分输入数据的部分
- 如果需要限定返回长度,请在提示词中明确指出
指令要求需要具体
如果提问/获得答案的人设明确,请在提示词中明确指出
需要LLM以什么样的格式输出,需要在提示词中明确提出
- JSON 格式输出时如何严格控制格式?
直接表述,要求输出格式为JSON
1
2
3
4
5
6请从分割线以下文本中抽取出指定schema的实体,要求如下:
*. 提取 {schema} 信息,并以JSON格式输出
*. json 格式如下:
{json}
-------------
{content}输出:
多数情况下输出会是JSON,但是调用样本数上来(样本数 10+)之后,会出现这样的输出:1
抽取结果: {json_output}
1
markdown\n{json_output}
1
json\n{json_output}
如果这个结果需要与下游系统进行集成,而下游系统期望得到的结果是标准的JSON输出,问题就出现了,对于上述这样不标准的输出,该如何处理?
直接的思路就是,返回的结果后做一下正则匹配和抽取,可行,但是不够优雅,那么还有没有更简单优雅的办法?
试一试按RFC JSON标准进行输出,会是怎样?1
2
3
4
5
6请从分割线以下文本中抽取出指定schema的实体,要求如下:
*. 提取 {schema} 信息,并以严格符合RFC8259标准的JSON格式输出
*. json 格式如下:
{json}
-------------
{content}实测,样本(样本数100+)都会稳定按照约定JSON格式输出。
- JSON 格式输出时如何严格控制格式?
需要明确告知LLM无法处理的情形下的行为
明确告知LLM哪些事情不能做
给LLM举个例子做示范通常会得到更好的结果(few-shot)
化繁为简
- 将复杂的任务拆分成多个简单的子任务
提示词相关概念
零样本(zero shot)
通过大量数据集训练并调整的LLM能够执行零样本任务,典型的例子就是判断一段话的情感分类(正面,负面和中性)
prompt:
1 | 将文本分类为中性、负面或正面。 |
output:
1 | 中性 |
原始论文 [^1]
少样本(few shot)
虽然LLM在一些简单场景中可以做到零样本提示,但是对于稍复杂的任务表现不佳,少样本提示可以作为一种技术,以启用上下文学习,我们在提示中提供演示以引导模型实现更好的性能。
如果用一句话概括少样本提示技术就是: “给LLM举例子来帮助他理解任务”, 一个示例就是1-shot,对于更复杂的例子可以尝试增加演示(例如: 3-shot, 5-shot, 10-shot等)。
prompt:
1 | A "whatpu" is a small, furry animal native to Tanzania. An example of a sentence that uses |
output:
1 | When we won the game, we all started to farduddle in celebration. |
思维链(Chain of Thought(CoT))
对于更复杂的推理任务,少样本依然不能很好地解决问题,请看以下这个问题 [^2]:
1 | The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. |
output:
1 | Yes, the odd numbers in this group add up to 107, which is an even number. |
显然,答案是不正确的,是样例给的少了么?增加一些样例(4-shots)我们来看看:
prompt:
1 | The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1. |
output:
1 | The answer is True. |
显然也依然不正确,如果增加更多的样例,可以要理由相信不会得到更好的提升。
我们仔细分析下就知道,这类的问题并不是通过一层逻辑就可以处理和判断的,换句话说这类任务其实是需要几步推理步骤才能解决的,解决这类问题就需要 思维链(CoT)。
另外,这类问题的特征是: 算数、常识和符号推理问题。
prompt:
1 | The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1. |
output:
1 | Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False. |
结果正确,那么减少一些示例可以得到结果么?
prompt:
1 | The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1. |
output:
1 | Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False. |
零样本思维链提示(zero-shot CoT prompt)
“让我们一步一步思考”(Let’s think step by step)魔法,在提示词中添加上述魔法词就可以在一类算数、符号推理问题中提升问题的准确度[^3]。
让我们看一个例子 (以下测试执行与 chatglm_turbo 单轮对话, temperature = 0.95, top_p = 0.7, maxtoken = 1024 test sites),首先是
没有使用魔法词的效果
prompt:
1 | Q: A juggler can juggle 16 balls. Half of the balls are golf balls, |
Output:
1 | 8 |
显然答案是错误的,那我们看下加了魔法词后的效果
使用魔法词后的效果
prompt:
1 | Q: A juggler can juggle 16 balls. Half of the balls are golf balls, |
Output:
1 | Half of the 16 balls are golf balls, so there are 16 / 2 = 8 golf balls. |
计划-解决提示(Plan-and-Solve Prompting)
先看一个例子:
1 | Q:在一个20人的舞蹈教室里,20%的学生参加了现代舞课程,剩下的25%参加爵士舞课程,其余的人参加了hip-pop课程,那么参加了hip-pop课程的学生占总体学生的比例是多少? |
如果我们使用zero-shot CoT 魔法词技巧:
1 | Q:在一个20人的舞蹈教室里,20%的学生参加了现代舞课程,剩下的25%参加爵士舞课程,其余的人参加了hip-pop课程,那么参加了hip-pop课程的学生占总体学生的比例是多少? |
Output:
1 | 首先,我们知道教室里有20人。 |
很显然答案是不对的,如果换一种处理提示方式:
1 | Q:在一个20人的舞蹈教室里,20%的学生参加了现代舞课程,剩下的25%参加爵士舞课程,其余的人参加了hip-pop课程,那么参加了hip-pop课程的学生占总体学生的比例是多少? |
Output:
1 | 首先,我们已知20%的学生参加了现代舞课程,25%的学生参加了爵士舞课程。那么,我们可以先从总数中减去这两个比例,以得出参加hip-pop课程的学生所占的比例。 |
这个答案就符合预期了,这类需要多步骤推理计算解决的任务提示词工程叫 Plan-and-Solve prompt[^8]
Auto-CoT
基于 “让我们一步步思考”(Let’s think step by step)在zero-shot CoT prompt 的应用效果,Auto-CoT 的主要思想就是准备一个类似问题数据集,然后通过计算相似度(向量距离)对问题数据集进行排序,再通过 zero-shot Cot prompt 生成few-shot prompt样例候选,然后从这些候选中选取样本并排序,与问题最后组成 few-shot CoT prompt。更多Auto-CoT 详情参考[^4]
总体上上述论文将这一过程描述为两个步骤 :
- Question Clustering
- Demonstration Sampling
Question Clustering 主要做样本的向量距离计算及排序
Demonstration Sampling 主要是遍历候选数据集,并使用 zero-shot CoT 技巧获取 (问题,推理,答案) 数据集对, 并按照实际选取标准组成 Few-shot Cot提示词
自我一致(self consistency)
自我一致的主要思想就是通过不同的思路去进行推理得出结果,然后通过选取出频度最高的答案,然后作为最后的答案。
自我一致性旨在“替换链式思维提示中使用的天真贪婪解码方法”。其想法是通过少样本CoT采样多个不同的推理路径,并使用生成结果选择最一致的答案。这有助于提高CoT提示在涉及算术和常识推理的任务中的性能。[^5]
OpenAI 自我一致例子
1 | question = """Q: 如果停车场里有3辆汽车,又有2辆汽车到达,停车场里有多少辆汽车? |
output:
1 | Answer: 0 |
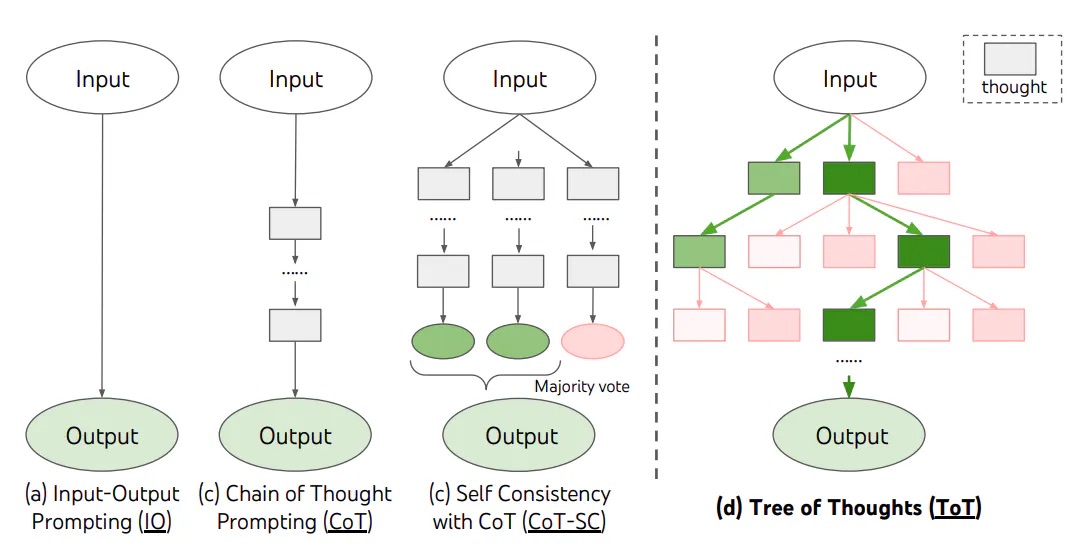
思维树(Tree of Thought)
对于需要探索或预判战略的复杂任务来说,传统或简单的提示技巧是不够的, TOT 基于思维链提示进行了总结,引导语言模型探索把思维作为中间步骤来解决通用问题。[^6]
检索增强生成 (Retrieval Augmented Generation (RAG))
要完成更复杂和知识密集型的任务,可以基于语言模型构建一个系统,访问外部知识源来做到。RAG的实现与事实更加一性,生成的答案更可靠,还有助于缓解“幻觉”问题。
RAG 把一个信息检索组件和文本生成模型结合在一起。RAG 可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练。[^7]
ReAct
ReAct 源自 ReasoningAction,是一种提示词框架,利用LLMs以交错的方式生成 推理追踪(reasoning traces)和任务相关动作(task-specific actions)。
生成推理轨迹使模型能够诱导、跟踪和更新操作计划,甚至处理异常情况。操作步骤允许与外部源(如知识库或环境)进行交互并且收集信息。
ReAct 在处理语言和决策相关任务上有着优异的表现[^9]
main prompt:
1 | Solve a question answering task with interleaving Thought,Action,Observation steps. |
Few-shot:
1 | Question What is the elevation range for the area that the eastern sector of the |
LangChain 的 ReAct 实现例子
1 | !pip install --upgrade openai |
1 | llm = OpenAI(model_name="text-davinci-003" ,temperature=0) |
1 | agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?") |
1 | I need to find out who Leo DiCaprio's girlfriend is and then calculate her age raised to the 0.43 power. |
自动推理并使用工具(Automatic multi-step Reasoning and Tool-use (ART) )
方向性激励提示(Directional Stimulus Prompting(DSP))
通过在提示词中添加 激励/提示 从而达到更好提取摘要效果的提示词框架, 其中 激励/提示 的生成是通过 Policy LangguageModel来生成,更多细节参考原论文[^10]
参考
- [^1]: Finetuned Language Models Are Zero-Shot Learners
- [^2]: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- [^3]: Large Language Models are Zero-Shot Reasoners
- [^4]: AUTOMATIC CHAIN OF THOUGHT PROMPTING IN LARGE LANGUAGE MODELS
- [^5]: SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS
- [^6]: Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- [^7]: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- [^8]: Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
- [^9]: REAC T: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
- [^10]: Guiding Large Language Models via Directional Stimulus Prompting
