系统设计常见组件 - Cache 篇
缓存使用的场景
常见使用缓存解决问题的场景是:
- 降低系统响应延迟
- 提高系统吞吐性能
第一个场景比较好理解,就是我们常见的追求“更快”,
- 数据库的查询更新缓存
- 应用实例热数据的缓存
- 静态资源的CDN缓存
- 浏览器的站点资源缓存
- DNS的本地缓存
都是这一类的场景。
缓存的常见设计模式
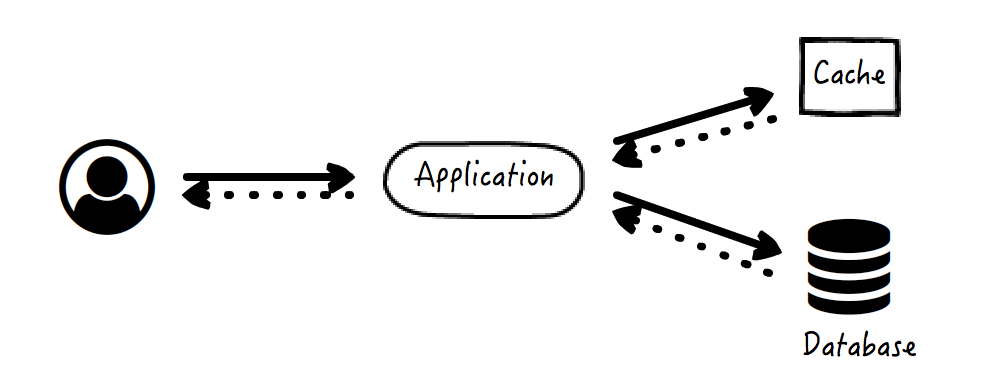
Cache aside
是最常见的缓存应用模式,整个过程也比较好理解。
- 应用先从缓存中查找是否有所需的数据
- 如果有直接返回数据
- 如果没有,从数据库中查找返回
- 然后应用将数据存入缓存
Cache aside 使用时需要注意的地方
缓存更新的操作
缓存更新的顺序是
- 先在数据库更新数据
- 再让对应的缓存失效
(图片来自 熊燚 - 全栈工程师修炼指南)
为什么一定是这样的顺序呢?如果先让缓存失效再更新数据库会有什么问题么?
先让缓存失效在没有并发的场景下也是可以的,但是如果是在高并发的场景下是会出现缓存读取数据与数据库数据不一致的现象。
为什么会出现不一致呢?我们考虑这样的一个场景,应用实例首先失效了需要更新的数据缓存,恰恰在应用去数据库更新数据期间又有一个请求来访问缓存,发现缓存失效,于是从数据库读取数据(此时的数据库更新事务并未提交)改时间点所读取的数据是未更新的过期数据,并将这个过期数据更新到了缓存中,数据库更新数据操作完成之后就出现了缓存与数据库数据不一致的现象,更严重的是如果没有其他机制保证,这个过期的缓存数据就再也没有时机与数据库数据进行同步和更新。
通过对cache aside 模式的描述,我们可以看出cache与应用实例之间是双向联系的,而与数据库之间是没有交互关系的,所以这个aside可以理解为aside在访问数据库路径。
下面的这个模式就与cache aside不同了,cache在应用实例与数据库之间扮演起了“中间人”的角色。
Read/Write through
在Read/Write through模式下,从应用实例的视角上看,cache与数据库是一体的,对于读取和更新数据的操作只需要和cache打交道,而数据库对它来说是透明的。

(图片来自 熊燚 - 全栈工程师修炼指南)
先看下Read through 数据获取的过程:
- 应用先从缓存中查询所需数据
- 如果缓存中有,则返回数据给应用
- 如果没有,缓存从数据库中读取然后将数据设置在自己的缓存中
- 然后缓存将数据返回应用
Write through数据更新的过程:
- 应用要求缓存更新数据
- 如果缓存中有数据那就更新数据
- 缓存更新数据库数据
- 缓存通知应用更新完成
对于写操作,在并发的场景下需要注意的是:缓存更新数据库的操作顺序应当与应用请求更新的顺序一致。
举个例子,有两个请求依次要把同一缓存更新为A和B,那么最终缓存应当更新为B(与数据库值一致)。这个一致性可以通过数据库的乐观锁来保证。
Read/Write through的策略往往是在有一些框架中实现,比如Java生态中的 Ehcache 就支持以上提到的所有策略Ehcache - caching patterns
Write behind (Write back)
Write behind 模式是缓存在更新完自己的数据后就直接返回了,而数据库的更新是异步进行的。
这样做的优缺点都很明显:
优点:
提高吞吐量,如果需要同步等待整个调用环中最耗时的操作完成,整个缓存的更新效率就会较低,同时在高并发的场景下会带来数据库的负载突然升高,出现峰值现象。
缺点:
由于缓存和数据库更新是分阶段异步进行的,所以数据的一致性问题无法从机制上保证。也就存在这种可能性:如果系统突然断电,还未来得及同步数据库的这段缓存就会出现不一致,这部分未持久化的数据修改就可能丢失。
缓存常见的问题
缓存穿透
缓存穿透指的是在某些情况下,大量对于同一数据的访问穿过缓存,但是缓存并没有起到应有的保护。
常见的例子就是对数据库不存在的数据进行查询,缓存如果对这个不存在的数据不做任何处理,那么这些数据就会穿过缓存直接将查询压力传递到数据库。
解决这个问题有两种思路:
- 最直接的思路就是,给这个不存在的值设置一个默认值存入缓存中,这样后面的读取就会从缓存中读取到默认值,而不会直接访问数据库。
- 使用BloomFilter,这种数据结构可以高效明确地告诉我们一个值的不存在。
当然这两种解决方案有各自的优缺点和使用场景:
| 方法 | 优点 | 缺点 |
|---|---|---|
| 回置默认值 | 简单直接 | 可能会有大量空值缓存,浪费缓存存储空间,进一步会造成缓存命中率下降 |
| BloomFilter | 海量数据使用有优势 | 占用内存资源大;引入运维成本 |
除了上面的这种场景之外,在高并发的场景下还有一种 Cache stampede(也称作 Dog Pile Effect)同样会有缓存穿透的问题。
对于缓存中的热key,缓存在更新过程中会有缓存失效,然后去数据库查询的过程,这个过程中如果有大量的并发读请求,就会穿过缓存直接到达数据库,严重的话会造成系统的瘫痪。
这种Cache stampede 问题的解决方法有两种:
- 利用分布式锁来进行流量控制的方式进行。
这里的分布式锁可以有多种选型考虑;缓存系统实现、Zookeeper实现等等。
- 缓存预热,在大批流量到来之前主动将缓存填充好,但这种方法的局限性就是,需要提前知道哪些数据可能引发数据穿透问题。
缓存雪崩
另一种常见缓存问题是缓存雪崩,在一定的时间内大批缓存失效,原本起屏障作用的缓存失去作用,形成系统压力穿透,引起系统过载、系统崩溃的现象。
应对缓存雪崩的方法与上面应对 Cache stampede 问题的思路类似:
- 限流,现象发生后保证系统只去承载接纳能够承载的系统压力。
- 缓存预热,在有现象预兆的时候事先加载一部分的热点数据。
还有一种特殊的缓存雪崩是我们在选择缓存加载和设置缓存失效的时候需要注意的,如果大批缓存数据在同一时间加载,并且设置了相同的过期时间,那么缓存系统在这个集中的时间点就会面临缓存雪崩的风险。
这类问题的解决方案也比较简单:
- 尽量避免集中缓存写入时间;
- 如果无法避免,那么就在缓存过期时间上加上(或者减去)一个随机时间,避免同一时间过期。
缓存设计的重点
- 可扩展的缓存系统设计需要有缓存集群,这个集群对于硬件的需求是内存大、存储性能好和网络带宽好
缓存本质上是一个内存和IO密集型的系统,所以在系统的硬件选型上需要有所侧重 - 需要根据业务的特点和数据监控将适合缓存的数据放入缓存系统。
- 缓存本质上是通过空间换时间的算法策略,同时也是通过牺牲数据的强一致性来换取的高性能,因此需要在使用缓存时需要评估是否是适合缓存的场景。
- 缓存内部往往会使用LRU策略,在LRU实现的时候考虑到线程安全的因素,需要在内部维护读写锁,这样会降低性能,需要注意。
- LRU的策略也是有缺陷的,如果用户在有意访问一些错误信息就会破坏这个最近访问数据的真实性,如果这样的操作是有组织上规模的(最典型的例子是网络爬虫)就会淘汰掉一些本应该贮存在缓存中的热数据,致使数据库压力突然上升。
